Most evaluations in AI report a simple result: what score each model got on which benchmarking task. When you deploy an agent, you're not just choosing a model. You're choosing a full system: what tools the agent can use, how it plans its steps, what it remembers between actions, how it recovers when something goes wrong. Change any of those and the same model can produce very different results at very different costs.
How well an AI agent works depends on how it's built, not just the model inside it.
Today we're launching the Open Agent Leaderboard, an open benchmark for comparing full agent systems, not just the models inside them. It reports both quality and cost, so you can see not just what works, but what's worth deploying.
The leaderboard is paired with the Exgentic framework for running and reproducing evaluations, and a paper describing the full methodology and results. Everything is open from day one.
Can we measure generality?
AI agents are getting really useful when carefully tailored to a specific job, like coding in a familiar repository or handling customer service with a known set of tools. But the harder question is whether the same agent can handle many different jobs, each with its own tools, rules, and constraints, without being manually customized for each one.
A more general agent is one you can drop into a new setting and have it just work.
That's what we mean by generality, and it's best understood as a spectrum, not a binary label. Of course, generality that only works in theory isn't useful. What matters is whether an agent stays capable as the range of jobs and settings grows, and whether it does so at a reasonable cost. A system that handles everything but costs a fortune to run isn't general in any way that matters.
This leaderboard measures exactly that: how general your agent actually is.
It evaluates agents across diverse, unfamiliar settings, each with different tools, rules, and constraints, and reports both quality and cost. So you can see not just how well a system performs, but whether it's worth actually deploying. It doesn't cover every capability a general agent will eventually need. But it's a much stronger test of how well agents work across different situations than anything previously available. And by treating the full agent system, not just the model, as the thing being measured, it makes visible what's actually driving the results.
What we built
We assembled six benchmarks, each testing a different kind of realistic task. Together they aim to capture a broad range of working settings: coding, customer service, technical support, personal assistance, and research.
SWE-Bench Verified-- fixing real bugs in real code repositoriesBrowseComp+-- researching complex questions across the webAppWorld-- completing personal tasks across hundreds of apps and actionstau2-Bench Airline & Retail-- customer service following company policiestau2-Bench Telecom-- technical support following company policies
Each is an established benchmark, created and reviewed by the research community. They weren't chosen because any single one captures general agency. They were chosen because together they test very different things: real code changes, open-ended research, broad action spaces, rule-bound conversations. That mix is what makes the evaluation meaningful.
These benchmarks were each designed to test one kind of task in one kind of way. Making them work together meant giving them a shared structure. We introduced a unified protocol that gives every benchmark the same shape: a task (what to do), a context (what to know), and a set of actions (what's allowed).
Instead of each agent speaking each benchmark's language, they all speak one.
This standardization isn't trivial. Each benchmark comes with its own assumptions, instructions, and interaction patterns. Making sure these don't clash with how different agents work internally requires deep understanding of both sides. It's one of the reasons this work took time, and one of the reasons results may differ from what you see on individual benchmark leaderboards. But the payoff is real: the benchmarks keep their original design, the agents keep their native tools and interfaces, and the protocol gives them a common way to connect.
task, context, and actions.
How to read the leaderboard
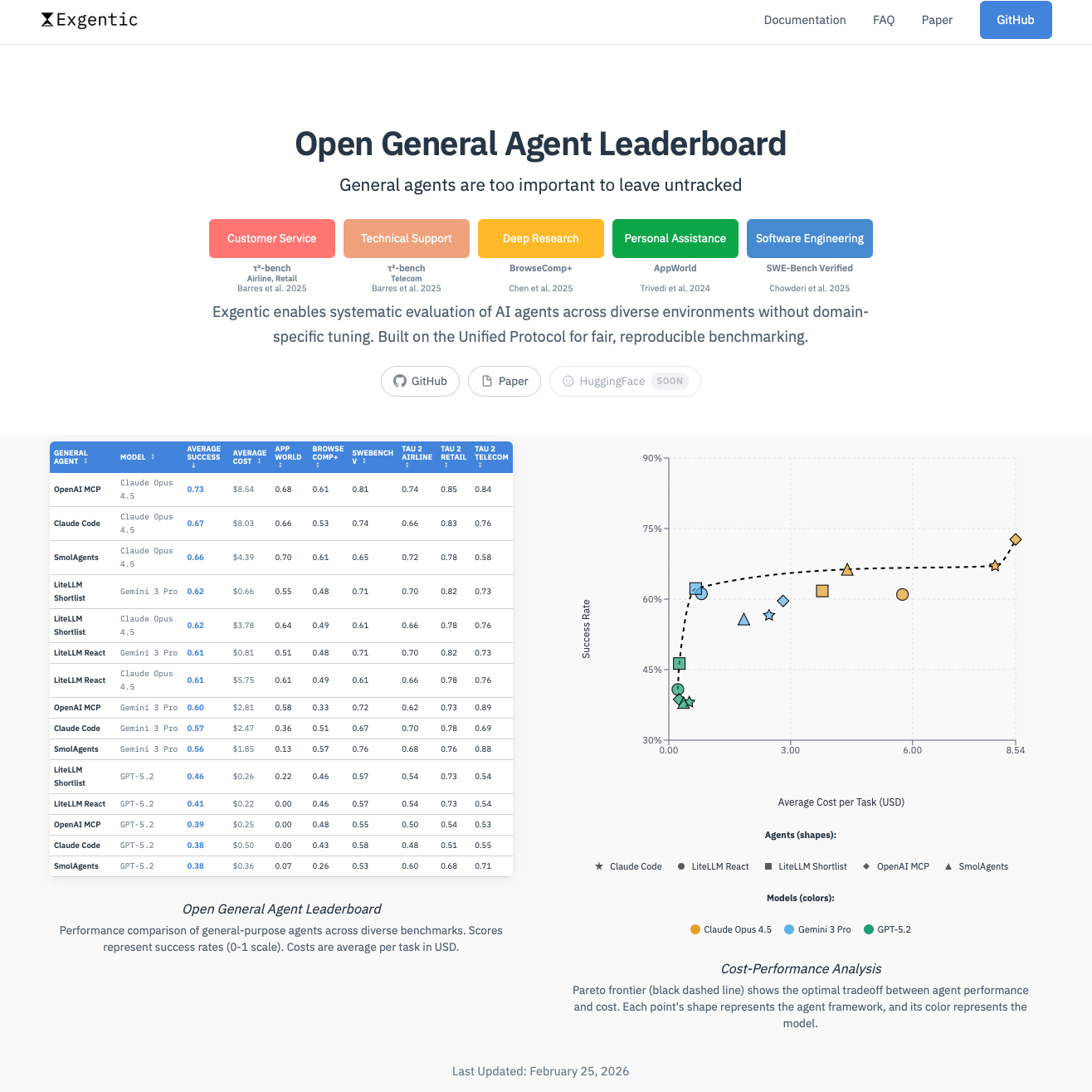
Each row is a full agent system: a specific agent paired with a specific model, evaluated across all six benchmarks. For every configuration, you see the average success rate, the average cost per task, and per-benchmark breakdowns.
Here's what the current top five looks like:
| Rank | Agent | Model | Success | Cost |
|---|---|---|---|---|
| 1 | OpenAI Soloopenai sdk 0.7.0 | Claude Opus 4.5 | 73% | $8.54 |
| 2 | Claude Codeclaude code 2.1.7 | Claude Opus 4.5 | 67% | $8.03 |
| 3 | Smolagentsmolagents 1.24.0 | Claude Opus 4.5 | 66% | $4.39 |
| 4 | ReAct + Shortlistingexgentic 0.1.0 / litellm 1.79.1 | Gemini 3 Pro | 62% | $0.66 |
| 5 | ReAct + Shortlistingexgentic 0.1.0 / litellm 1.79.1 | Claude Opus 4.5 | 62% | $3.78 |
Look at the top three. All use the same model. Yet they differ in both score and cost because the agent systems wrapped around that model are different.
Same model, different agents, different results -- the agent matters.
The cost gap is just as striking. The most efficient configuration in the top five runs at a fraction of the price of the strongest one. The full picture becomes clear when you plot every configuration by quality and cost:
When the agent implementation is visible alongside the model, you can start to untangle what's driving the results: which gains came from the model, which from the agent design, and which components generalize across settings. That's what this leaderboard is built to show.
A note on results: agents here are tested as general-purpose systems without benchmark-specific tuning, and without the prompt and environment optimizations that model developers often apply to individual benchmarks. So scores may differ. See the paper for details.
What we're already learning
One finding surprised us: general-purpose agents are already competitive with specialized ones. In several cases, agents with no benchmark-specific tuning matched systems built directly for those tasks.
Across most benchmarks, general agents match or even outperform the best specialized systems. A single agent can increasingly handle many kinds of work, not just the one environment it was prepared for.
The results also reveal something you can't see from success rates alone: agents differ dramatically in how they fail. Some fail fast and cheap. Others burn through long, expensive runs before giving up. In our experiments, failed runs cost 20--54% more than successful ones. For anyone running agents in production, failure behavior shapes your bill just as much as success does.
Perhaps the most important finding is about what drives the results. Model choice is still the dominant factor. But agent architecture is already making a visible difference. Tool shortlisting, helping the agent focus on relevant tools instead of searching through everything, improved performance across every model we tested and turned otherwise failing configurations into viable ones.
Today the model explains most of the results. But the agent around it is already starting to change the outcome.
The full methodology and empirical analysis are described in our paper on general agent evaluation.
What's public today
Everything behind this leaderboard is open. Today we're releasing:
- The Open Agent Leaderboard -- explore the results directly
- Exgentic -- run and reproduce evaluations yourself
- The paper -- full methodology and empirical analysis
We built this for the community. Explore, submit your own agent, and help us make agent evaluation more open and more useful for everyone.
What we want from the community
General agents are too important to be evaluated behind closed doors.
General agents are modular systems: planning, memory, tool use, context management, error recovery. The results above show that these components make real tradeoffs across cost, reliability, and performance. If one component is doing the heavy lifting, the community should be able to see that.
We built Exgentic to make this kind of open evaluation practical: an open platform that orchestrates cross-environment benchmark sessions and produces standardized results, trajectories, and cost reports. But we can't build this alone.
Agent developers can open up their systems by versioning changes, documenting what's inside, and making components configurable. Benchmark creators can help expand the range of settings we evaluate against. And anyone can reproduce our results, challenge them, and find what we missed.
Not all of this is easy yet. Most benchmarks weren't designed with general-purpose agents in mind and require careful adaptation. This is an evolving project, and feedback on what needs to be easier is just as welcome as a finished contribution.
What's next
We're actively expanding the benchmarks, the agents, and the models on the leaderboard.
A key priority is evaluating open-source models. Understanding how open models compare to proprietary ones across diverse agent settings matters for the whole community, and we're working to make that a core part of the leaderboard.
We're also adding new benchmarks like WebArena Verified, and already experimenting internally with agents like Codex CLI and Gemini CLI.
This opens up some of the most interesting questions ahead. Is Claude Code better with Claude? Is Gemini CLI better with Gemini? Or do some models simply perform well regardless of the agent wrapped around them? This leaderboard is built to answer exactly these kinds of questions, and we'll have results to share soon.
Closing
General-purpose agents deserve evaluation that reflects what's actually being measured: the full system, not just the model.
The Open Agent Leaderboard is a starting point. We believe it can become something bigger: a shared standard for how the community evaluates, compares, and improves open agent systems.
Explore the leaderboard. Read the paper. Try Exgentic. And if this direction resonates, help us build it.
General agents are reshaping the way work is done. Let's research and discuss them openly.
Related reading
- General Agent Evaluation -- ICLR 2026 Workshop Paper
- Ready For General Agents? Let's test it. -- ICLR 2026 Blog Post
- Position: Agentic Systems Should be General -- ICLR 2026 Workshop Paper